ChromeV8是如何工作的
Chrome V8 是如何工作的
我们知道,V8 是 Google 开源的 JavaScript 引擎,被广泛应用于各种 JavaScript 执行环境,比如 Chrome 浏览器、NodeJS、Electron 以及 Deno。但是,很多前端开发人员对 V8 的理解还停留在表面,只是单纯地使用 JavaScript 和调用 Web API, 并不了解 V8 这个黑盒内部是如何工作的。我们只有搞清楚这个问题,才能写出性能更好,更优雅的 JavaScript 代码。
同时,了解 JavaScript 的执行原理,也能够让你更轻松的理解 Babel 的词法分析和语法分析原理、ESLint 的原发检查机制、React 和 Vue 等前端框架的底层实现,以后你在面对其他新的技术和新框架,也能够以不变应万变。

所以,我们先从宏观上学习 V8 架构的演进历史,了解 V8 是如何演进成如此成熟的架构,然后在此基础上深入学习 V8 执行 JavaScript 过程中的词法分析、语法分析、解释器、优化编译器的工作机制及原理,让我们知其然并知其所以然。
V8 架构演进
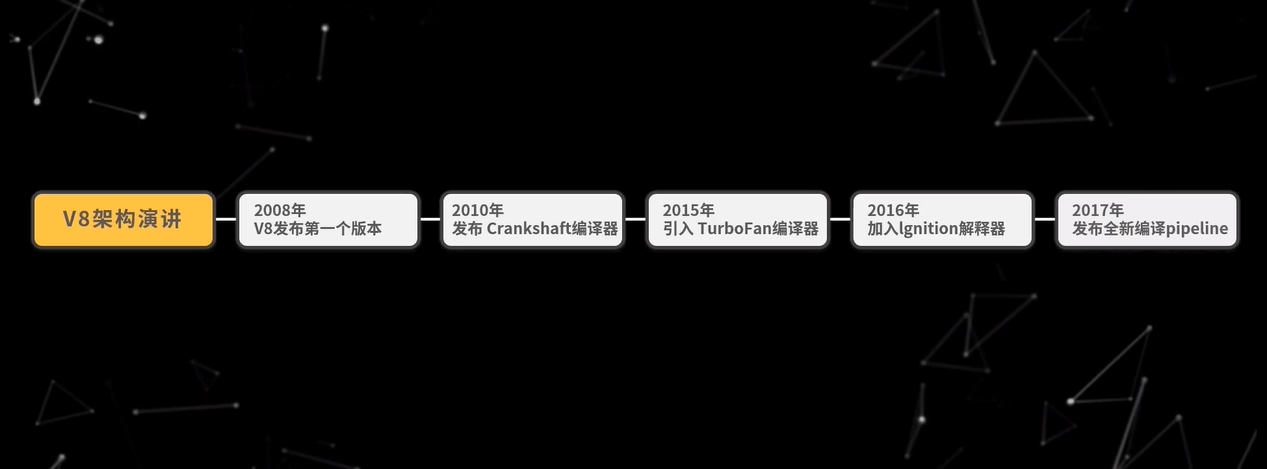
2008 年,V8 发布了第一个版本,V8 刚一发布,其性能远超同时期竞争对手,比如 SpiderMonkey、JavaScriptCore,关注度非常高。不过,当时 V8 架构比较激进,是直接将 JavaScript 代码编译为机器码并执行,所以执行速度很快。
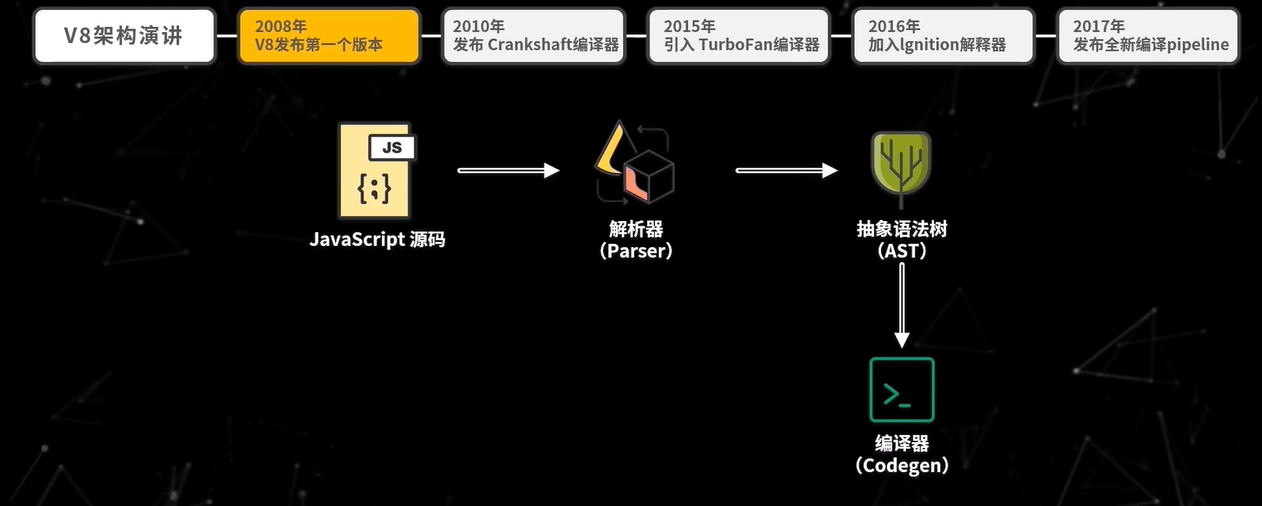
但在这个结构中,V8 只有 Codegen 一个编译器,对代码的优化很有限。所以在 2010 年 V8 发布了 Crankshaft 编译器,JavaScript 函数通常会先被 Full-Codegen 编译器,如果后续该函数会被多次执行,那么就是用 Crankshaft 再重新编译,生成更优化的代码,之后就是用优化后的代码来执行,进而提升性能。
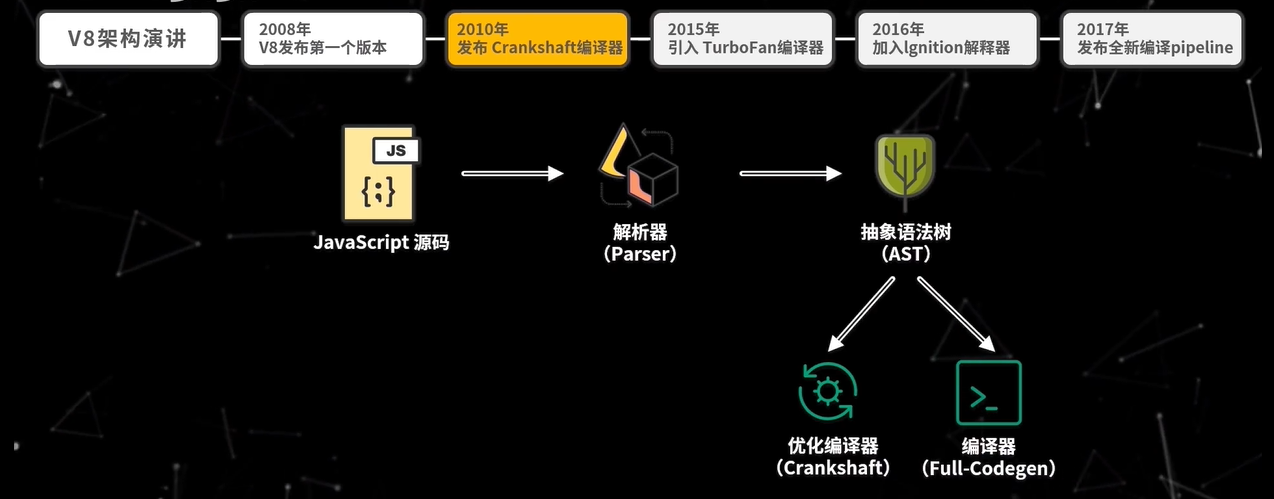
但是 Crankshaft 对代码的优化有限, 所以 2015 年 V8 中加入了 TurboFan。
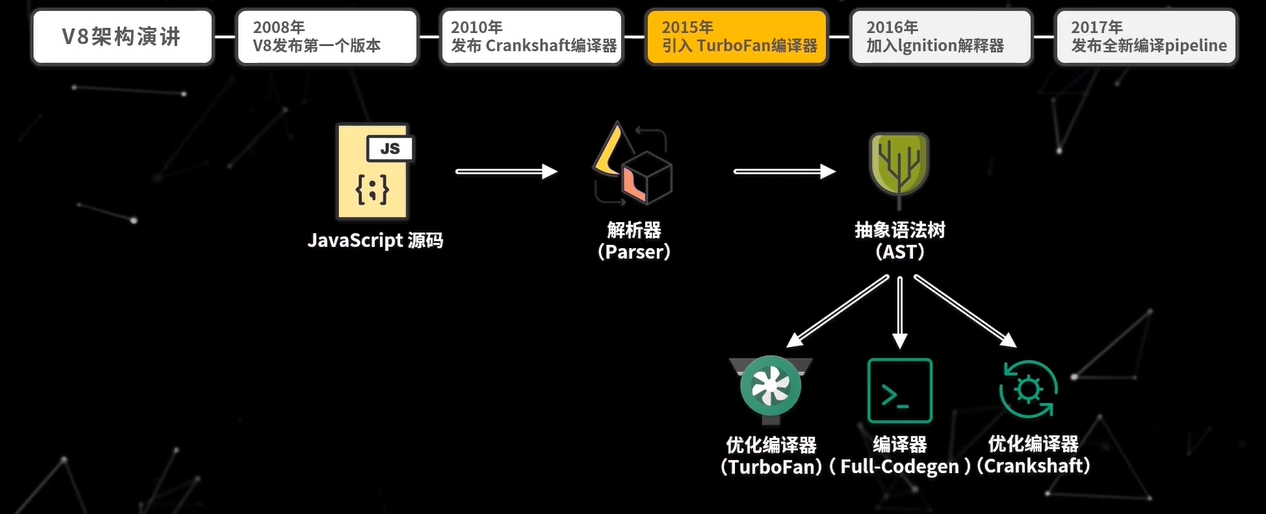
这时的 V8 依旧是直接将源码编译为机器码的架构,这种架构存在核心问题是内存消耗过大,尤其是在移动设备上,通过 Full-Codegen 编译出来的代码,几乎占整个 Chrome 浏览器的三分之一的内存,这样为代码运行时留下的内存就更少了,于是 2016 年 V8 加入了 Ignition 解释器,重新引入了字节码,旨在减少内存使用。
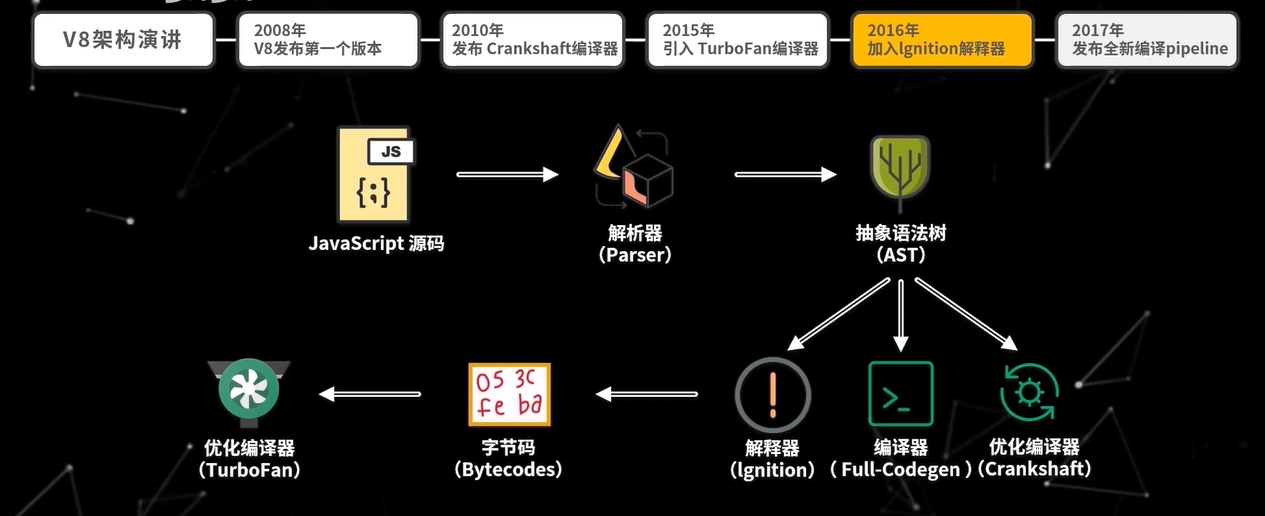
2017 年 V8 正式发布全新编译 pipeline,也就是使用 Ignition 和 TurboFan 的组合来编译执行代码。从 V85.9 版本开始,早期的 Full-Codegen 和 Crankshaft 编译器就不再用来执行 JavaScript 代码,在最新的架构中,最核心的就三个模块:解析器(Parser)、解释器(Ignition)、优化编译器(TurboFan)。
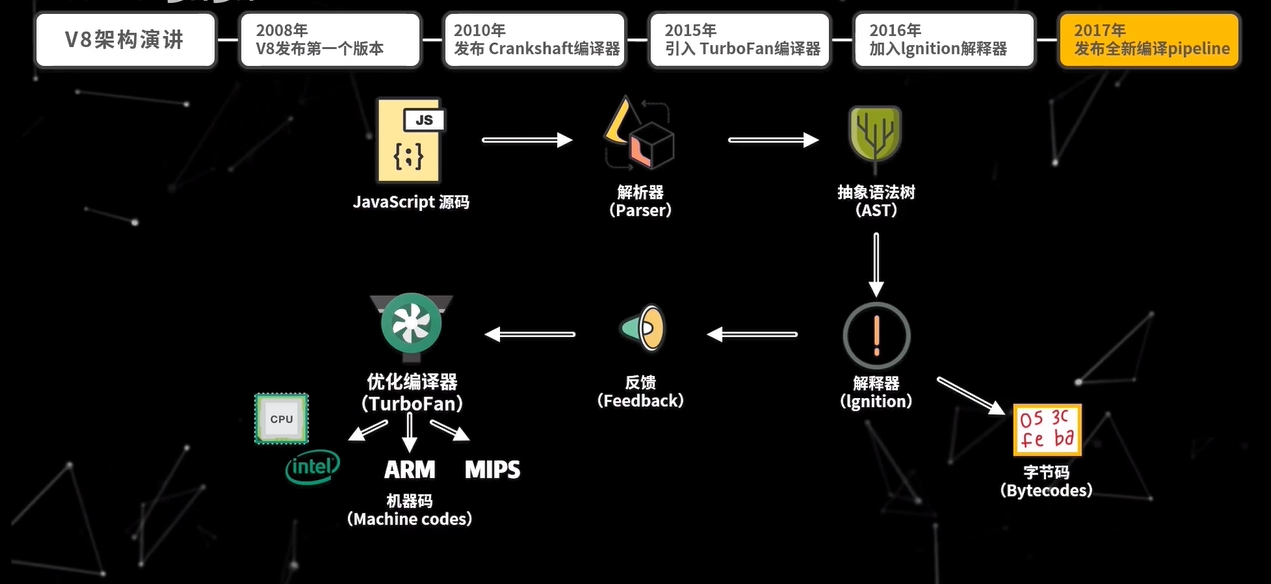
所以,接下来我们从解析、解释、编译三个部分触发,深入学习 V8 中 JavaScript 的代码执行逻辑。
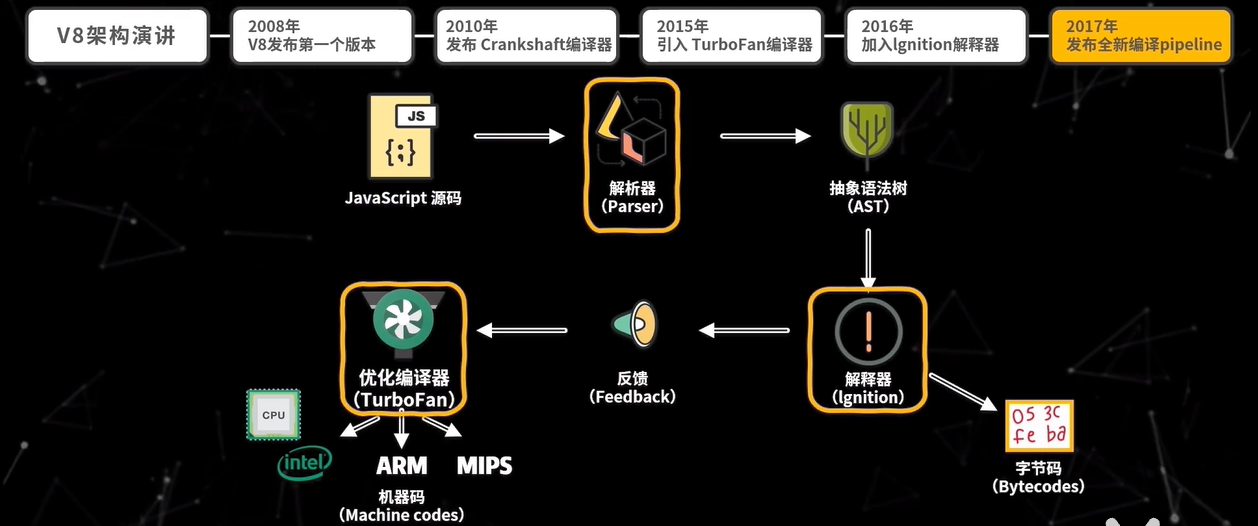
当 V8 执行 JavaScript 源码时,首先解析器会把源码解析为抽象语法树(Abstract Sytntax Tree),然后解释器再将 AST 翻译为字节码,一边解释一边执行,在此过程中,解释器会记录特定代码片段的运行次数,如果运行次数超过某个阈值,那么这段代码就被标记为热代码(Hot Code),并将运行信息反馈给优化编译器,优化编译器根据反馈信息优化并编译字节码,最终生成优化后的机器码。这样,当该段代码再次执行时,解释器就直接使用优化机器码执行,不用再次解释,从而大大提高了代码运行效率,这种在运行时编译代码的技术也被称为即时编译(JIT),通过 JIT,可以极大提升 JavaScript 代码的执行性能。
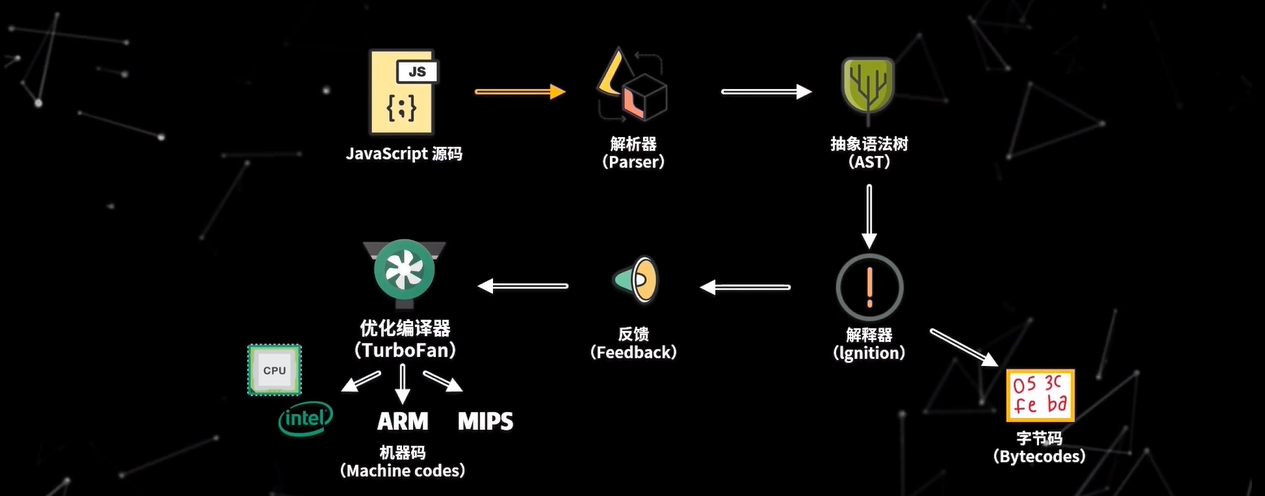
那么解析器是如何把源码转换为 AST 呢?首先我们要清楚,要让 V8 执行我们编写的源码,那么就要将源码转换为 V8 能理解的格式,V8 首先会把源码解析为一个抽象语法树(AST),抽象语法树是用来表现源码树结构的对象,这个过程称为解析(Parsing),主要由 V8 的 Parser 模块实现,然后 V8 的解释器会把 AST 编译为字节码
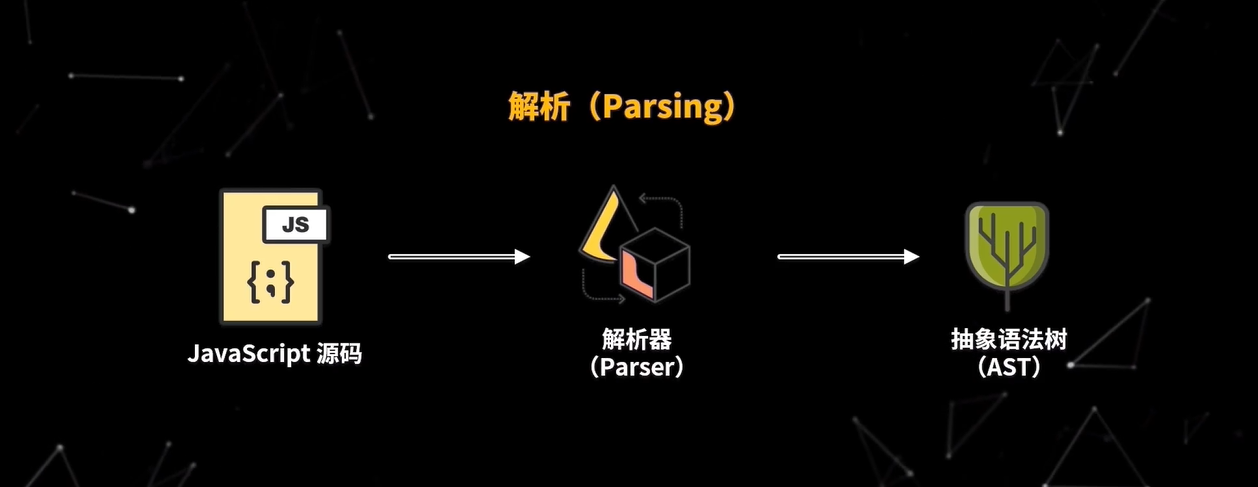
解析和编译过程的性能非常重要,因为 V8 只有等编译完成后才能运行代码,整个解析的过程可以分为两部分:
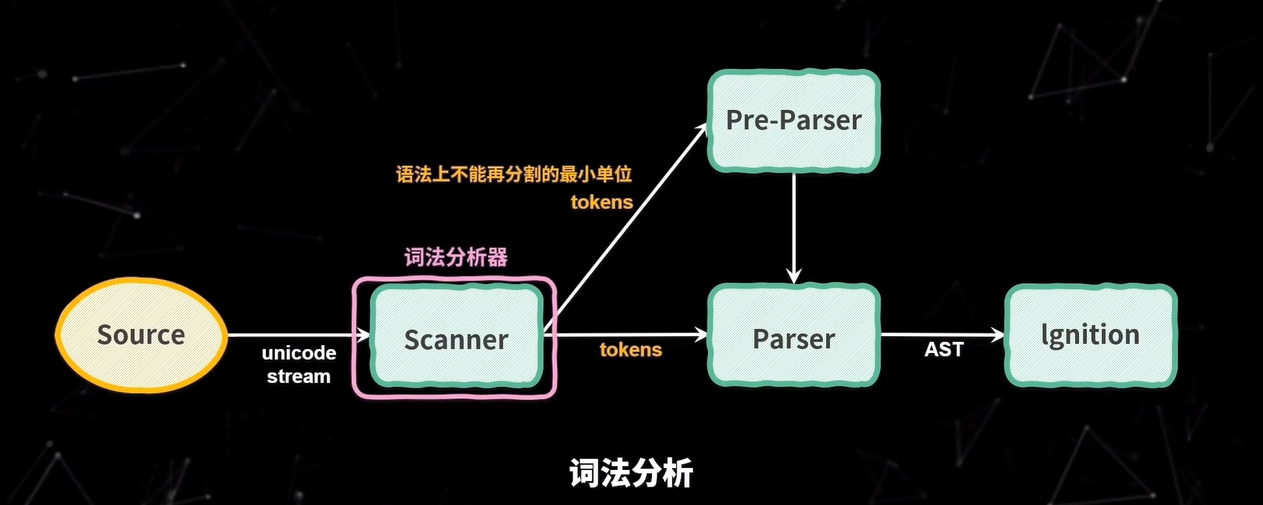
- 第一部分词法分析(Lexical Analysis),词法分析就是将字符流转换为 tokens,字符流就是我们编写的一行行代码,token 是指语法上不能再分割的最小单位,可能是单个字符,也可能是字符串,图中的 Scanner 就是 V8 的词法分析器
- 第二部分语法分析(Syntax Analysis), 语法分析是根据语法规则将 tokens 组成一个有嵌套层级的的抽象语法树,在这个过程中,如果源码不符合语法规范,解析过程就会终止,并抛出语法错误。图中的 Parser 和 Pre-Parser 都是 V8 的语法分析器。
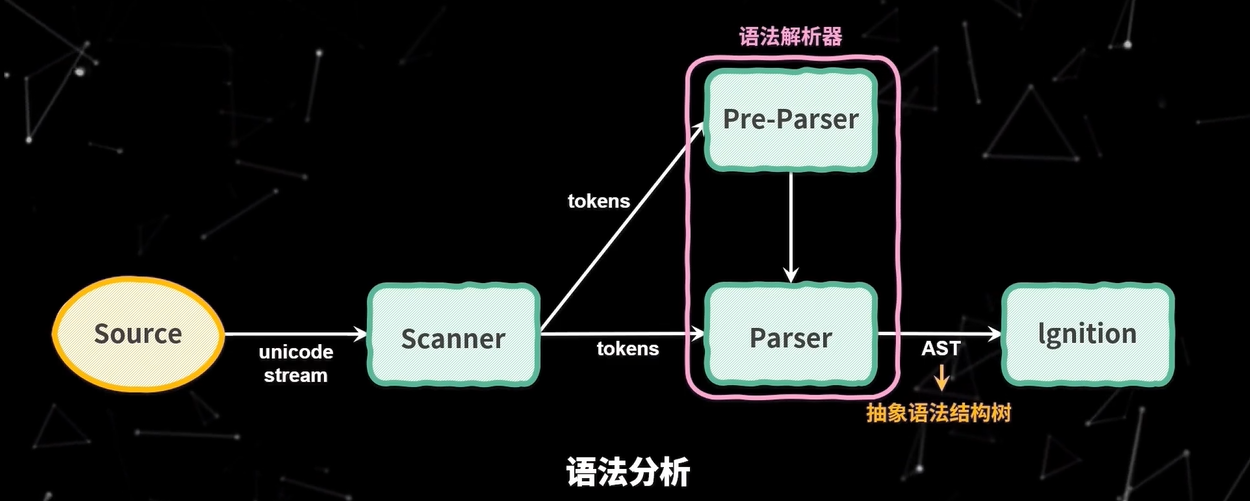
接下来我们就详细看一下词法分析和语法分析
首先是词法分析,在 V8 中,Scanner 负责接收 Unicode 字符流,并将其解析为 tokens,提供给解析器使用。比如var a = 1;这行代码词法分析后得 tokens 如下
1 | [ |
可以看到,我们这行代码包括 5 个 tokens: 关键字var, 标识符a,赋值运算符=, 数字1以及分隔符;
加下来,V8 解析器会通过语法分析,根据 tokens 生成 AST,这行代码生成的 AST 如下
1 | { |
你也可以在在线工具上修改代码,观察 AST 的结构
但是,对于一份 JavaScript 源码,如果所有源码在执行前都要完全经过解析才能执行,那必然会面临三个问题:
代码执行时间变长,因为一次性解析所有代码必然会增加代码的运行时间
消耗更多内存,因为解析完的 AST 以及根据 AST 编译后的字节码都会放在内存中,这样必然会消耗更多的内存
占用磁盘空间,因为编译后的代码还会缓存在磁盘上,所以会重用磁盘空间

因此,现在主流的 JavaScript 引擎都实现了延迟解析, 延迟解析的思想很简单,就是在解析过程中,对于那些不是立即执行的函数,只进行预解析(Pre-Parser),只有当函数调用时才对函数进行全量解析。进行预解析时,只验证函数的语法是否有效,解析函数声明以及确定函数作用域,不生成 AST。

实现预解析的就是 Pre-Parser 解析器, 以如下代码为例
1 | function foo(a, b) { |
由于 Scanner 是按字节流从上往下一行行读取代码,所以 V8 解析器也是从上往下解析代码,当 V8 解析器解释到函数声明时,发现他不是立即执行的,会使用 Pre-Parser 解释器对其预解析,这个过程中,只会解析函数声明,不会解析函数内部的代码,不会为函数内部的代码生成 AST,然后 Ignition 解释器会把 AST 编译为字节码并执行,解释器也会按照自上而下的顺序执行代码,先执行var a = 1;和var b = 2;两个赋值表达式,然后再执行函数调用foo(1, 2);, 这是 Parser 解析器才会继续解析函数内的代码并生成 AST,再将该 AST 交给 Ignition 解释器编译执行。
那么解释器(Ignition)是如何将 AST 翻译为字节码并执行的呢?在 V8 架构的演进中,V8 为了解决内存占用问题引入了字节码,如图

通常,一个几 KB 的文件转换为机器码可能就是几十兆,这回消耗巨大的内存空间,所以 V8 引入了字节码。V8 的字节码是对机器码的抽象,其语法与汇编有些类似,你可以把 V8 字节码看成一个个指令,这些指令组合在一起,就实现了我们编写的功能。
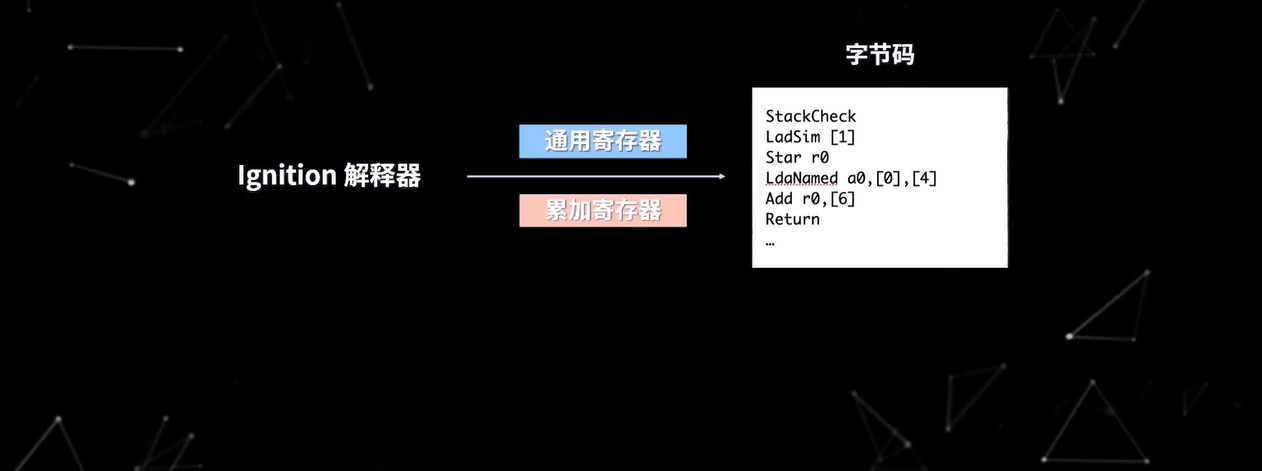
V8 一共定义了几百个字节码,你可以在 V8 解释器的头文件中查看所有的字节码,Ignition 解释器在执行字节码时, 主要使用了通用寄存器和累加寄存器,其中,函数参数和局部变量都保存在通用寄存器中,而累加寄存器用于保存中间结果,让我们来看一段代码来进一步学习字节码的执行流程
1 | function f(a, b, c) { |
首先,我们定义了一个含有三个参数的函数 f,函数的功能就是对参数进行计算,并返回值。
假设我们以参数 5, 2, 150 调用这个函数,那么 Ignition 解释器首先会把函数编译为字节码,执行node --print-bytecode test/index.js > bytecode.txt来查看 JavaScript 文件生成的字节码输出到bytecode.txt文件,打开该文件直接查看文件末尾的字节码如下
1 | ...... |
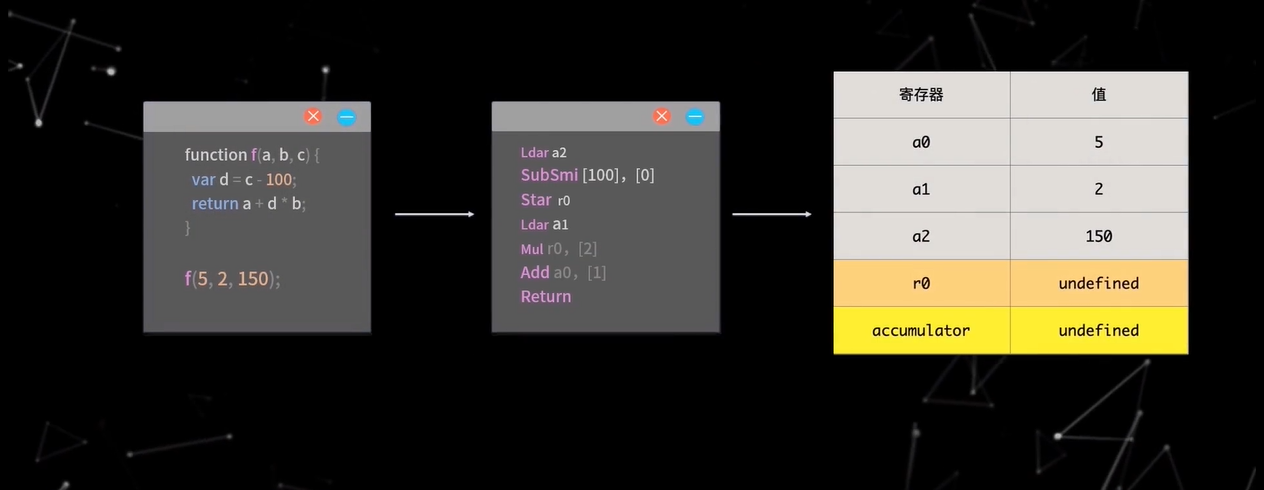
如图所示,当 Ignition 解释器执行代码时,首先会把参数分别加载到 a0, a1, a2 寄存器上,图中的 accumulator 表示累加寄存器,然后在逐行执行字节码。Ldar a2表示将 a2 寄存器的值加载到累加寄存器中,加载后,累加寄存器的值就变为了 150SubSmi [100]表示将累加寄存器的值减少 100,这时累加寄存器的值就变为了 50,[0]表示反馈向量(FeedBack Vector)的索引,反馈向量就记录了函数在执行过程中的一些关键数据。Star r0表示把累加寄存器的值保存在寄存器 r0 中,这时 r0 的值就变为了 50,Ldar a1表示将 a1 寄存器的值加载到累加寄存器中,这时累加寄存器的值就变为了 2,Mul r0, [2]表示将累加寄存器的值与 r0 寄存器的值相乘,并将结果再次放入累加寄存器,其中[2]同样是反馈向量,执行完毕后,accumulator 的值就变成了 100,Add a0, [1]表示将累加寄存器的值与 a0 寄存器的值相加,并将结果再次放入累加寄存器,这是 accumulator 的值就变成了 105,Return 表示结束当前函数的执行并返回累加寄存器中的值。所以最终函数的执行结果时 105

这里需要注意的是,Ignition 解释器在执行字节码时,依旧需要将字节码转换为机器码,因为 CPU 只能识别机器码,虽然多了一层字节码的转换,看起来效率低了,但是相比于机器码,基于字节码可以更方便进行行性能优化。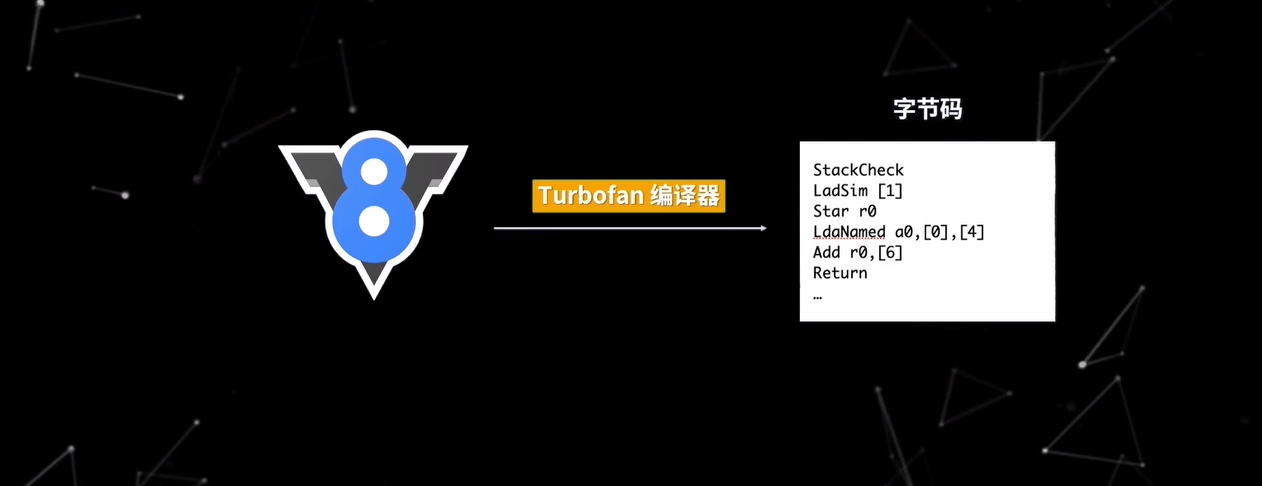
而 V8 的确也做了很多性能优化的工作,其中,最主要的就是使用 TurboFan 编译器编译热点代码,这些性能优化,使得如今基于字节码架构的行呢个优化要远超当年直接编译机器码架构的性能
Ignition 解释器在解释执行的过程中,会标记重复执行的热点代码,这些被标记的代码,会被 TurboFan 编译器编译生成效率更高的机器码,那么 TurboFan 编译器具体是怎么工作的呢?
其中,主要有两个算法,一个是内联,一个是逃逸分析,我们先看看内联
1 | function add(x, y) { |
上面的代码如果未经优化,直接编译该段代码,会分别生成两个函数的机器码
但为了进一步提升性能,TurboFan 编译器就会对以上两个函数进行内联,然后再编译

由于函数内部的行为就是求 1 和 2 的和,所以这段代码就有了改变
1 | function three_add_inlined() { |
更进一步,由于函数 three_add_inlined 中的 x 和 y 的值都是确定的,所以 three_add_inlined 还可以优化,直接返回结果 3
1 | function three_add_const_folded() { |
最终编译生成的机器码相比优化前就少了非常之多,执行效率自然也高了很多。
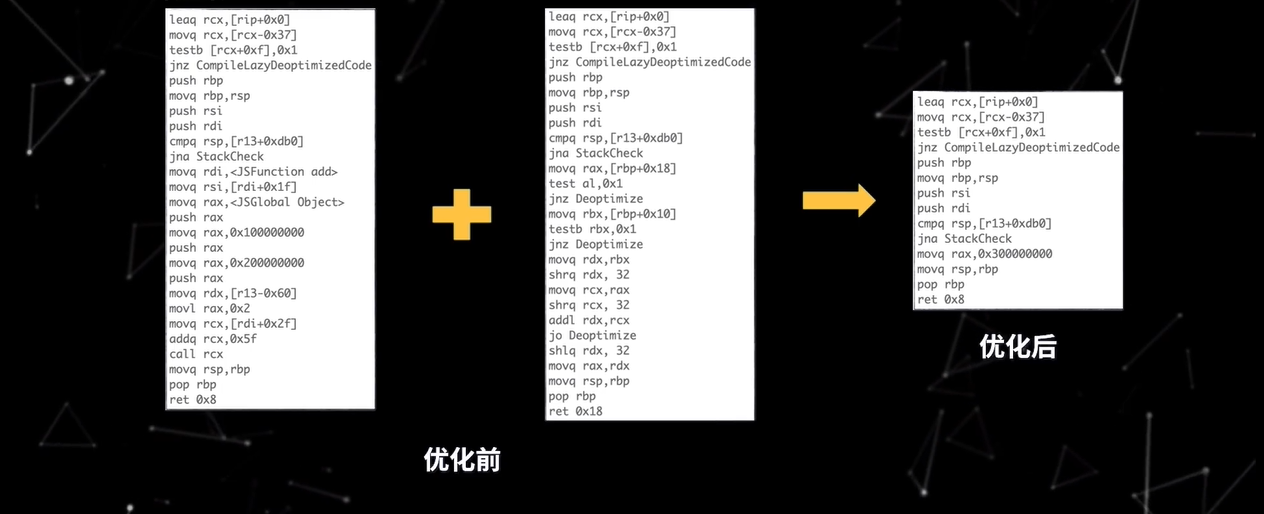
通过内联,可以降低复杂度,消除冗余代码,合并常量,并且内联技术通常也是逃逸分析的基础。那么什么是逃逸分析呢?

简单来说,它是指分析对象的的生命周期,是否仅局限于当前函数
让我们在来看一个简单的例子
1 | class Point { |
TurboFan 编译器首先会通过内联,将 manhattan 函数转换为如下函数
1 | function manhattan_inlined(x1, y1, x2, y2) { |
这样函数看起来就简单多了,再接下来,就会对 manhattan_inlined 中的对象进行逃逸分析
什么样的对象会被认为是“未逃逸”的呢?主要要满足如下两个条件:
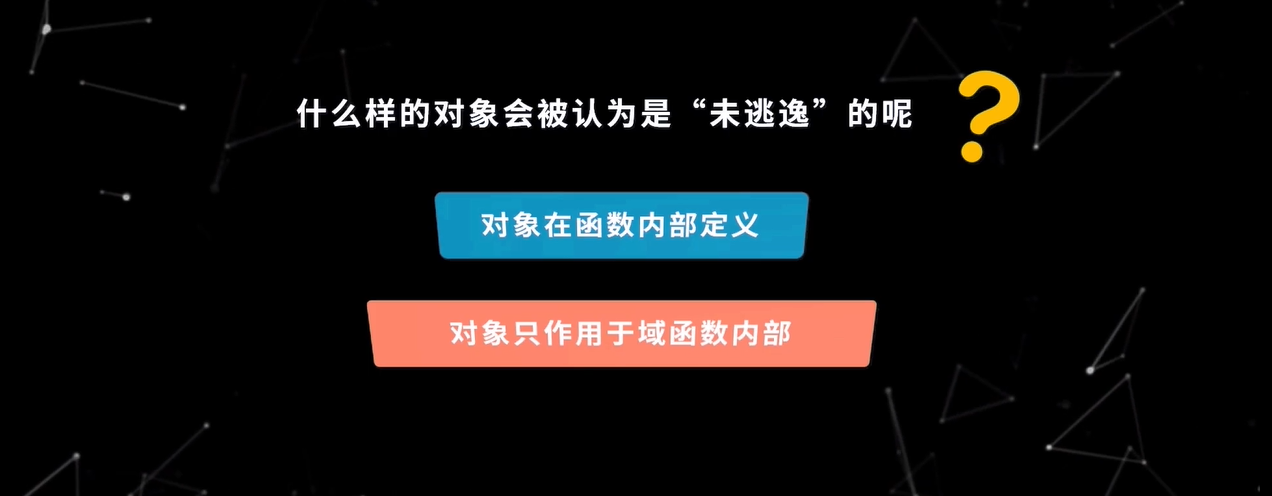
首先,对象是在函数内部定义;其次,对象只作用于函数内部。比如,函数没有被返回,也没有传递或者给其他函数调用
在 manhattan_inlined 函数中,变量 a 和 b 都是函数里内部普通变量,所以他们都是未逃逸对象,那么我们就可以对函数中的对象进行替换了,使用变量替换掉对象,这样函数内部就不再有对象定义,取而代之的是 a_x, a_y, b_x, b_y,并且直接来源于函数参数
1 | function manhattan_scalar_eplacement(x1, y1, x2, y2) { |
这样做的好处就是,我们可以直接将变量加载到寄存器上,不再需要从内存中访问对象了,提升了执行效率的同时,还减少了内存的使用
总结
- V8 架构演进史
最初,V8 是没有字节码的,直接将 JavaScript 源码编译为机器码执行,这种架构导致内存占用过高
后来引入了字节码
- V8 执行 JavaScript 的原理
大致分为第三个步骤
首先,解释器将 JavaScript 源码解析为 AST,解析过程分为词法分析和语法分析,V8 通过预解析提升执行效率
然后,解释器 Ignition 根据 AST 生成字节码并执行,这个过程中会收集反馈信息,交给 TurboFan 进行优化编译,TurboFan 根据 Ignition 收集的反馈信息,将字节码编译为优化后的机器码,后续 Ignition 用优化机器码代替字节码执行,进而提升性能
 wechat
wechat alipay
alipay
